Alteryx Design Pattern: Reshaping data with duplicate field names
In this Design Pattern we are going to show you how to reshape data where there are repeating fields which have the same name. This is a common structure that you may encounter when new data is added to the right, for example when a new month is added.
Below is a screenshot of the data used in the example:
| City | Date | Sales | EBITDA | Date | Sales | EBITDA | Date | Sales | EBITDA |
| London | 2020-01 | 100 | 10 | 2020-02 | 120 | 12 | 2020-03 | 150 | 15 |
| New York | 2020-01 | 150 | 15 | 2020-02 | 170 | 17 | 2020-03 | 200 | 20 |
| Paris | 2020-01 | 200 | 20 | 2020-02 | 220 | 22 | 2020-03 | 250 | 25 |
For each new month new fields for Date, Sales and EBITDA are added to the right of the dataset. However to make this useful for analysis the data needs to be reshaped into a flat file.
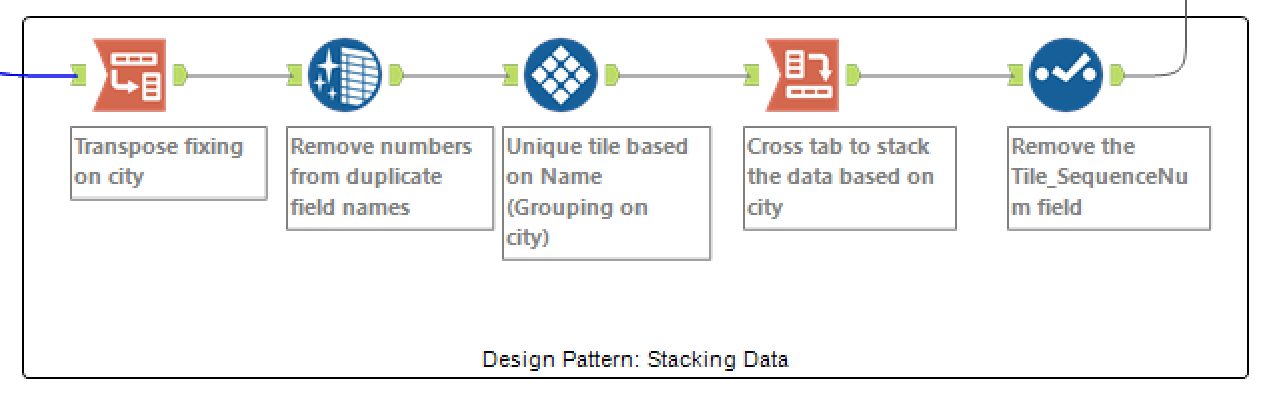
Using a similar Design Pattern as shown in posts such as How to modify many field values at the same time we use the combination of a transpose and cross tab tool to reshape the data. In between the ‘transpose and cross tab bookends’, we first put a Data Cleanse tool to strip out the number suffix which is added by Alteryx when there are multiple fields with the same name. Next we add a Tile Tool to get a number sequence which helps maintain the data order when the data is cross-tabbed.
In addition in the video, to maintain the field order a bonus trick is used with selecting no records from the input data and using this as the first input into the union tool.