Alteryx Design Pattern: Parsing HTML Tables
Use Case:
I have spoken with many users tasked with parsing HTML or XML data, serialized data, or even unstructured data, and many of them end up doing this task with 10-20 tools just to data munge it down to the values that they want. I have found that many of these users go down this road of using so many tools basically because they either:
- a) Haven’t seen the true power of RegEx and its capabilities, or
- b) It scares them…. like scary monsters under your bed type of scary.
Hopefully, I can help or at least challenge you not to shy away. I fully realize I am likely going to start a full-scale street riot amongst a few of you by going so far in saying this, but I have learned that RegEx is actually quite easy. Yep, I just said that.
If there is any interest, I could expand on this more in the future, but there are many posts and threads already on the community and great training videos as well. Now for those of you still with me, I am going to show you a great design pattern example having to do with tables that reside on a webpage.

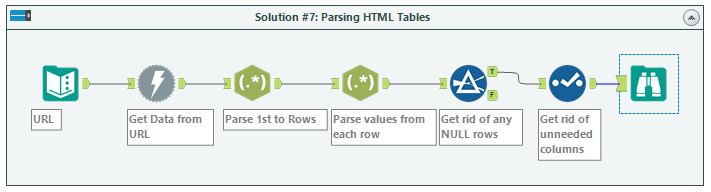
The main idea is super simple:
- Get your data (the HTML)
- Parse to Rows (while also filtering down to only what you want)
- Parse to Columns (while also removing any of the tags and stuff that is not the data)
- Clean up rows
- Clean up columns
Steps:
- Input Data with only URL
- Use Download tool to ‘scrape’ HTML from webpage
- Use the RegEx tool to parse out using the <tr> tags. (Notice I am splitting to rows, not columns)
- Use the RegEx tool to pull out only the values you want
NOTE: Steps 3 and 4 are just great examples of why the RegEx tool is so powerful. Also pay attention to the fact that I figured out what the RegEx expression is to parse out all the pieces, but more importantly, I put parentheses around only what I wanted to “Parse” out into the columns. I use https://regex101.com/ every time I am building the expression, then just pop it in the RegEx tool. Looks something like this: